
Scaling Trust: The Enterprise Governance Blueprint Powered by Unity Catalog
Author: Rajesh Kotian
Scaling Trust: The Enterprise Governance Blueprint Powered by Unity Catalog
Why Unity Catalog Is the Governance Layer Every Enterprise Needs
Data is most efficient and reliable when backed by strong data governance and a well-thought-out operating model that enhances its usability and value. If you are leveraging enterprise data using Databricks, then Unity Catalog serves as the de facto governance intelligence platform for managing data across the organisation.
Today, with the rise of AI, data products, and lakehouse architectures, trust has become eminent. Trust must be built in. Quality must be intentional. Governance must be active, not passive.
This is precisely where Unity Catalog shines, especially when combined with the underused superpower that will define the next decade of data management:
Semantic Tags – Together, Unity Catalog + Tags create a governance layer that not only protects data but also enhances data quality, AI readiness, observability, automation, and compliance.
Top Technical Data Governance Issues Breaking Enterprise Data Platforms
Let’s start with a common problem every organisation grapples with:
- Inconsistent Schemas Across Domains:
Different teams produced copies of an identical dataset, resulting in inconsistencies in column data types, naming conventions, and missing fields. This led to failures in downstream pipelines and machine learning models whenever upstream schema drift transpired. - Uncontrolled PII Exposure Across Workspace:
Sensitive fields such as email addresses, DOB, TFN, Medicare numbers, and addresses were stored in multiple uncontrolled tables with no classification or masking. This created compliance risks (GDPR, CDR) and inconsistent access patterns across users. - Shadow Data Products with No Ownership:
Critical datasets were duplicated across various workspaces without a designated owner or steward. Consequently, stakeholders relied on conflicting versions across reports and dashboards, leading to inconsistent decision-making. - No End-to-End Lineage or Impact Analysis:
When changes occurred upstream (e.g., API feed modification or datatype shift), teams had no visibility into which tables, dashboards, or ML models were affected. This led to reactive firefighting and prolonged incident resolution times. - Unstandardised Quality Enforcement Across Pipelines:
Bronze → Silver → Gold pipelines enforced different data quality rules across domains, with no central repository for visualising or registration. This led to unpredictable quality issues and made it impossible to certify any dataset with confidence. - Multiply Duplicated Data Assets Inflating Storage and Compute:
Without a central governance plane, teams created redundant Bronze, Silver, and Gold tables and duplicated entire datasets for their own pipelines, increasing storage, compute, and costs without governance oversight.
This is precisely the pain point that every enterprise feels but rarely articulates.
Unity Catalog Shifts the Centre of Gravity
Instead of writing endless rules in PySpark, SQL, or dbt, you capture the “truth about data” in one place, the governance control plane.
The power lies in UC’s ability to apply policies and standards at:
- Catalog level
- Schema (domain) level
- Table level
- Column level
And then propagate that metadata across every downstream consumer:
- DLT pipelines
- BI dashboards
- Lakehouse
- Sharing & clean rooms
- AI models
- Observability platforms
- Data products
- AI-powered agents
This governance metadata becomes the source of truth for quality rules, access controls, SLAs, and semantics.
Tags: The New DNA of Data Governance
Tags in Unity Catalog are simple on the surface. Under the hood, they are the metadata that drives quality automation.
Semantic tags examples: They’re actionable metadata instructions, not annotations.
Imagine a pipeline that reads a tag and responds:
“This is a {dq_critical = true} field. I’ll activate stricter expectations.”
Or a dashboard:
“This table has {pii = true}; mask these values for non-privileged users.”
Or an AI assistant:
“This dataset has {sla_freshness = 1hr} which requires hourly freshness; it’s now 3 hours old, raise an incident.”
Governance-Powered Quality Propagated across Medallion architecture
Tags inform quality at each stage of the Medallion architecture, i.e. Bronze, Silver and Gold Layer. When the data is transformed or reused, the tags are pushed across the outputs, keeping lineage information or properties consistent across
Let’s look at the tag-driven approach across the Medallion architecture.
| Bronze: Ingestion & Protection
|
Silver: Standardisation & Enhancement
|
Gold: Trusted & Certified Data Products
|
| Purpose: Land raw data safely, detect issues early
|
Purpose: Clean, structure, and conform data using business rules
|
Purpose: Serve governed, certified, analytics-ready data products |
Tags Driven Automation:
Example: Finance Raw Table { “layer”: “bronze”, “source_system”: “erp_finance”, “ingestion_method”: “batch_file”, “schema_enforced”: “true”, “cloudfiles_validation”: “enabled”, “file_type”: “csv”, “pii_detection”: “enabled”, “dq_required”: “true”, “freshness_sla”: “24h”, “drift_monitoring”: “disabled”, “sensitivity”: “pii”, “owner”: “finance_data_eng”, “domain”: “finance” } |
Tags Driven Automation:
Example: Sales Fact Table (Cleaned) { “layer”: “silver”, “domain”: “customer”, “record_uniqueness”: “customer_id”, “standardization”: “complete”, “schema_enforced”: “true”, “deduplication”: “enabled”, “null_handling”: “strict”, “dq_critical”: “true”, “dq_ruleset”: “customer_standard_rules”, “sensitivity”: “pii”, “pii_columns”: [“email”, “phone_number”, “address”], “lineage_trusted”: “true”, “owner”: “customer_steward_team” } |
Tags Driven Automation:
{ “certified”: “true”, “trust_level”: “high”, “sla_freshness”: “1h”, “business_domain”: “finance”, “data_product”: “revenue_reporting”, “dq_status”: “passed”, “quality_score”: “97”, “dq_critical_columns”: “[‘customer_id’,’revenue_amount’]”, “usage”: “analytics”, “consumer_group”: “executive_reporting”, “product_status”: “active”, “version”: “v3.2”, “retention_policy”: “7_years”, “certified_by”: “finance_stewardship”, “last_quality_review”: “2025-01-12” } |
| Outcome: Clean, safe, policy-aligned raw data | Outcome: Reliable, standardised data with enforced DQ |
Outcome: High-trust, consumption-ready data products |
Core Principle to Remember: Unity Catalog = Technical Governance/Enterprise DG Tool = Business Governance
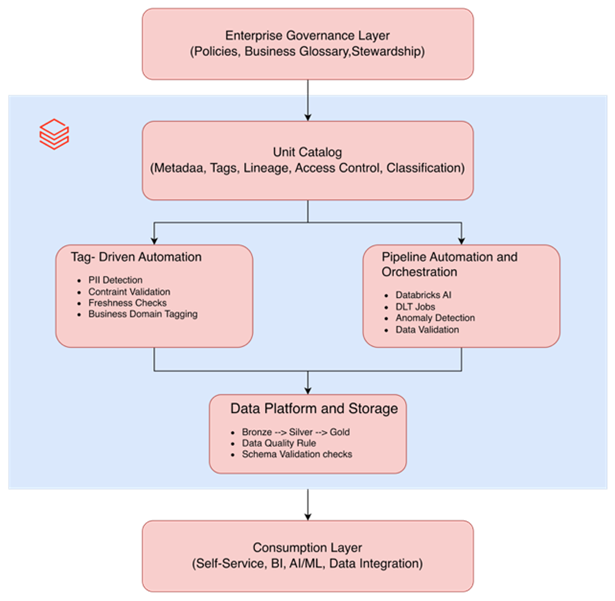
Unity Catalog and the Enterprise Data Governance tool do not compete. They operate at different levels of abstraction.
| Layer | Unity Catalog | Enterprise DG Tool |
| Purpose | Technical governance & security | Business governance, glossary, compliance |
| Audience | Engineers, platform teams, ML/DataOps | Analysts, stewards, governance leads |
| Controls | Access, masking, lineage, schemas, DLT rules | Glossary, policies, approval workflows |
| Source of Truth For: | Metadata about data assets | Metadata about meaning |
| Automation | Policy enforcement | Stewardship workflows |
| Integration | Pushes metadata to DG tool | Reads lineage & schema from UC |
Conclusion: The Metadata Layer Is the New Quality Engine
Unity Catalog’s tagging capabilities unlock an enterprise data governance vision where:
- Metadata becomes the operating system.
- Governance becomes the engine.
- AI becomes the enforcer.
- Data products become certifiable.
- Trust becomes measurable
The result?
A Lakehouse that is not just centralised and governed, but intelligent, self-correcting, and trustworthy by design.
If you’re looking to strengthen your organisation’s governance and platform strategy, 👉Contact our friendly team today for a no-obligation discussion.