
Author: Sallie Worsley
This cheat sheet offers a quick reference for getting started with PySpark, covering some core operations like loading, transforming, saving data, joins, and filtering. It’s designed for beginners working in Databricks or Fabric, focusing on fundamental concepts to help you build a starting foundation in PySpark.
Overview
A DataFrame in Spark is a collection of data organised into rows and columns, like a table in SQL. DataFrames contain a structure known as a Schema, which defines the column names and data type.
Note: You’ll need to adjust the file location based on your specific environment and any mount points that have been set up. Below is a simple guide to help you find a basic file location for testing.
Databricks
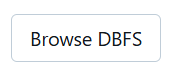
You will see the folder structure, and you can upload CSV files or other file types to Databricks using the Upload button.
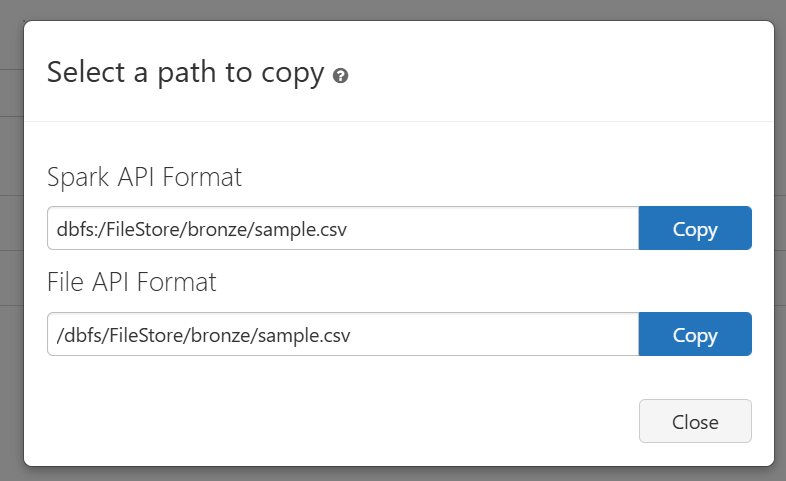
Once the file is uploaded, click the down arrow next to the file and select Copy Path to get the file path
Fabric
Navigate to your Lakehouse. Select the arrow next to Upload, and then upload your file
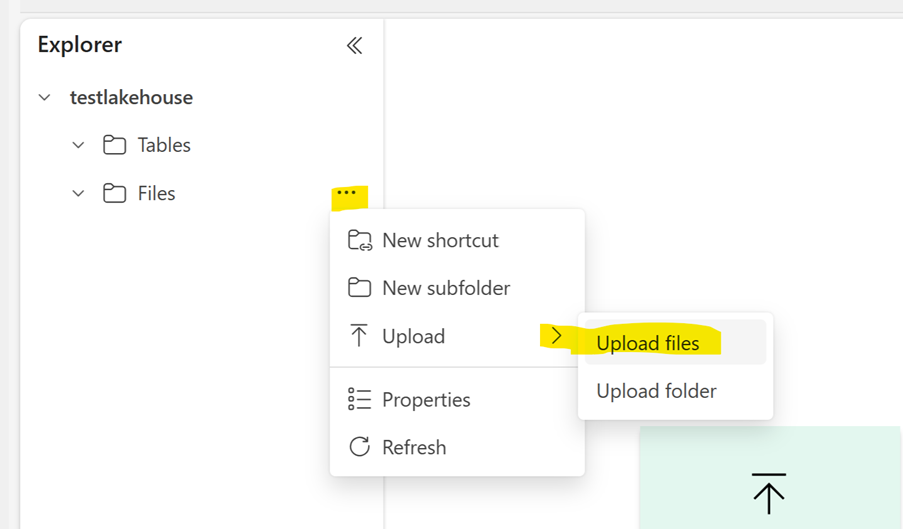
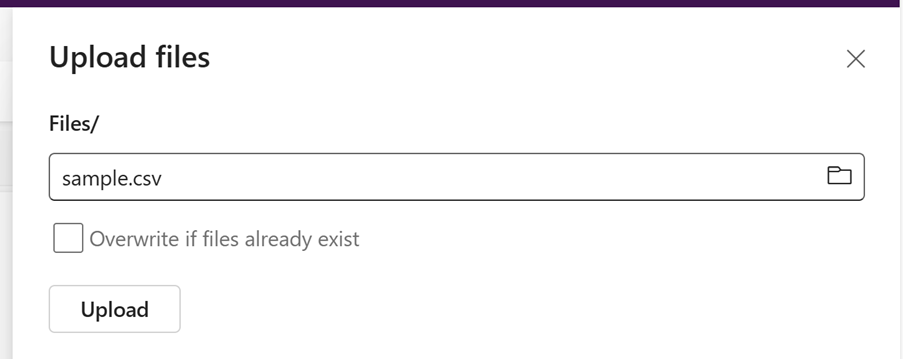
Navigate to the file and select Copy Relative Path for Spark
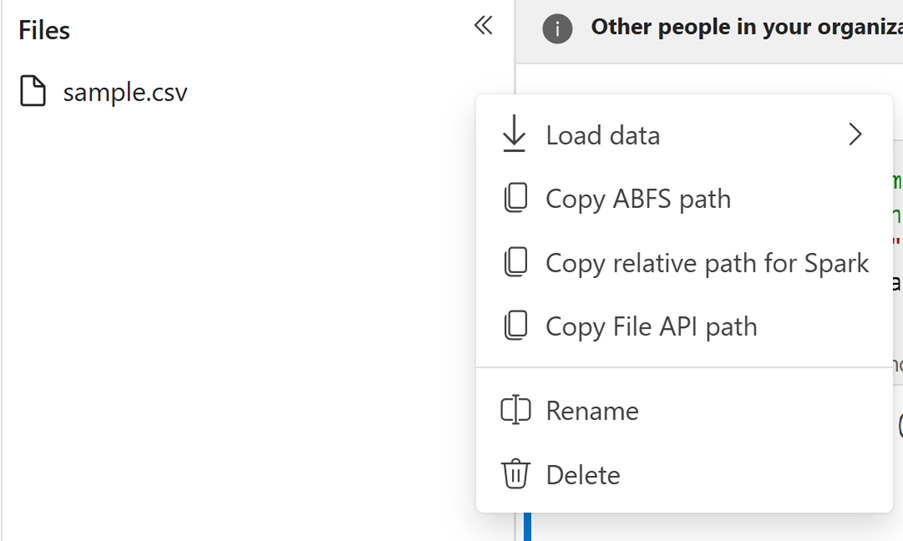
Loading Data in Spark
In this section, you’ll learn how to load CSV files into Spark DataFrames using PySpark. Whether you’re working on Databricks or Microsoft Fabric, the process is similar, but the file paths differ depending on platform.
-
Loading a CSV File
-
A) Databricks:
dataframe_df = spark.read \
.option(“header”, True) \
.option(“inferSchema”, True) \
.csv(“dbfs:/FileStore/bronze/sample.csv”)

-
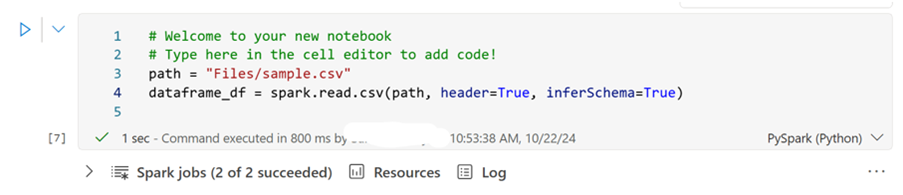
B) Fabric:
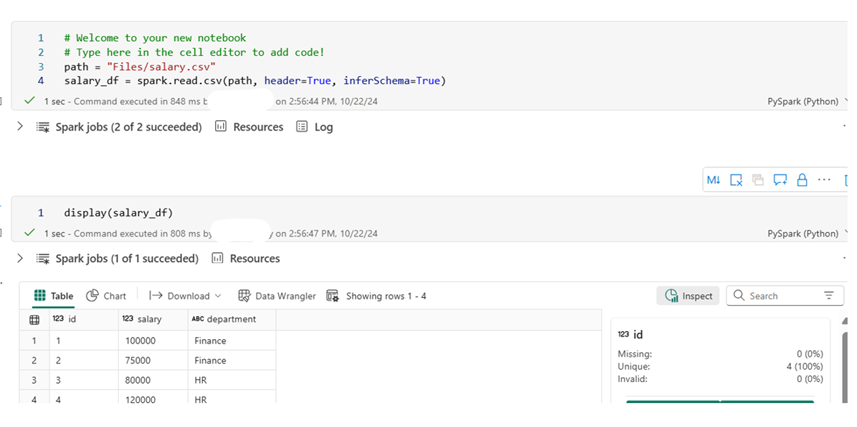
path = “Files/sample.csv”
dataframe_df = spark.read.csv(path, header=True, inferSchema=True)
Key Terms:
- header = True: Treat the first row as column names.
- inferSchema = True: Automatically infer column data types
-
Check Schema: Once the data is loaded, it’s useful to verify that Spark has correctly interpreted the schema. To check the schema, you can use one of the following methods. Please note we are using the name of the dataframe identified above:
- printSchema(): Show schema in an easy-to-read format.
Databricks
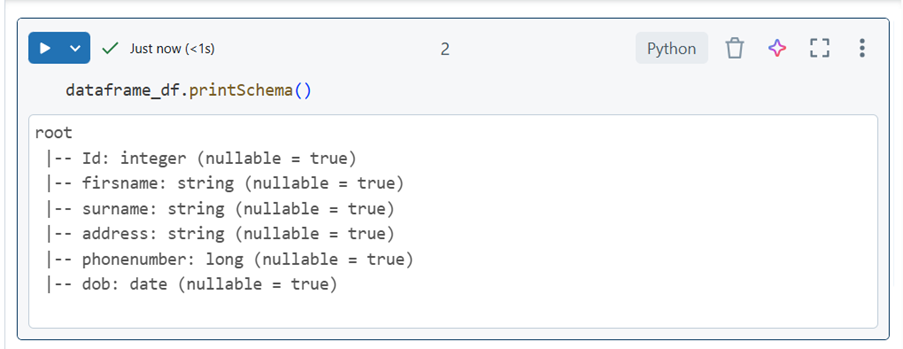
Fabric

-
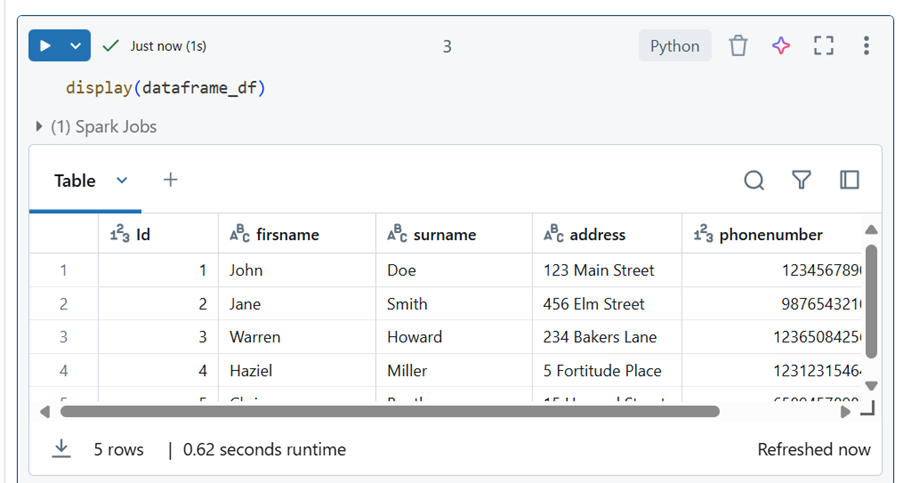
Display Data: You can use the following command to display DataFrames:
display(dataframe_df)
Databricks
Fabric
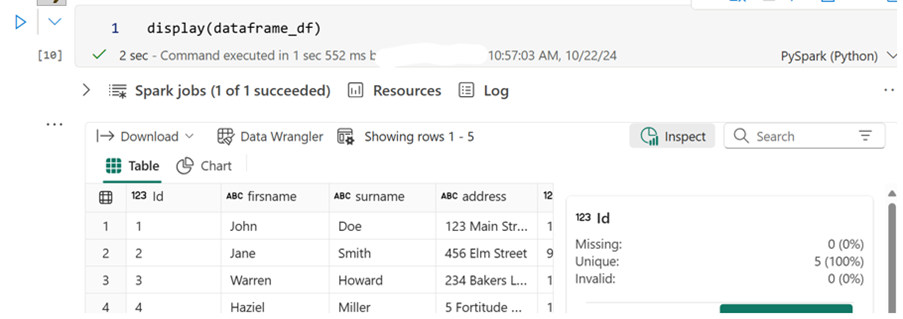
The dataframe_df is an example name of a created DataFrame.
-
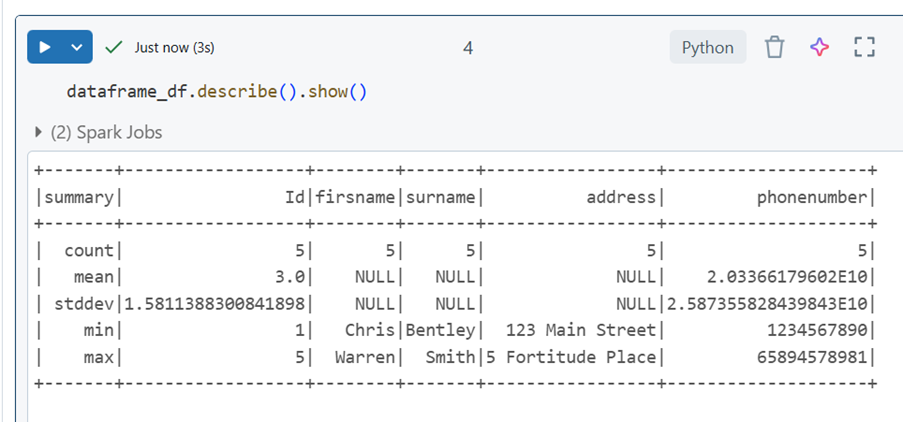
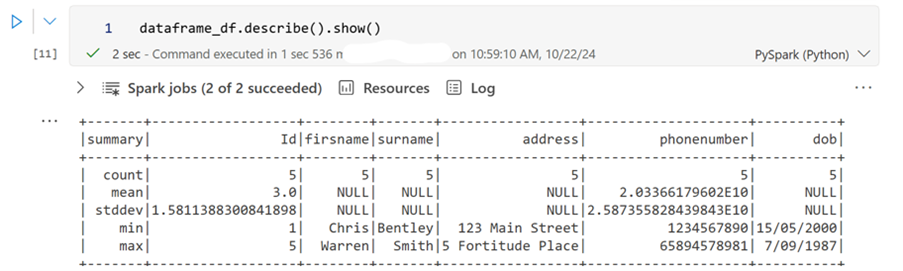
Describe Data: The describe() method returns a description of the data in the DataFrame.
dataframe_df.describe().show()
Databricks
Fabric
-
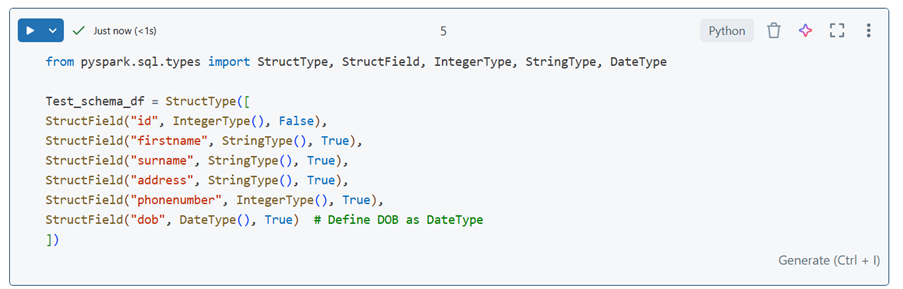
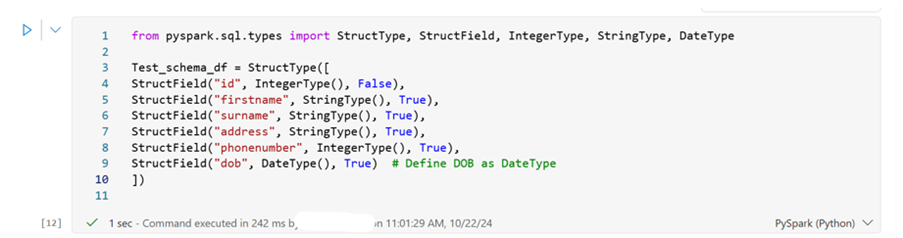
Defining Schema: You can define a schema manually using StructType and StructField.
Step 1 Import the required modules
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, DateType
Step 2 Define the Schema
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, DateType
Test_schema_df = StructType([
StructField(“id”, IntegerType(), False),
StructField(“firstname”, StringType(), True),
StructField(“surname”, StringType(), True),
StructField(“address”, StringType(), True),
StructField(“phonenumber”, IntegerType(), True),
StructField(“dob”, DateType(), True) # Define DOB as DateType
])
Databricks
Fabric
Key Terms
- StructType: This is used to define the schema of a DataFrame.
- StructField: This is used to define each column in the schema.
- IntergerType, StringType, DateType: These specify the data types of the columns.
- False/True: These indicate whether the column can contain null values (False means it cannot be null, True means it can be null)
-
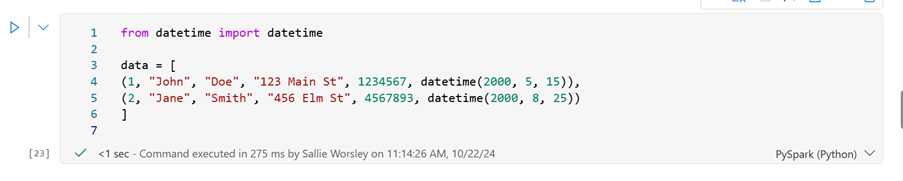
Sample data: You can create sample data and load it into a DataFrame with the schema defined:
Step 1: Import the required modules
from datetime import datetime
Step 2: Create Sample data
from datetime import datetime
data = [
(1, “John”, “Doe”, “123 Main St”, 1234567, datetime(2000, 5, 15)),
(2, “Jane”, “Smith”, “456 Elm St”, 4567893, datetime(2000, 8, 25))
]
Databricks

Fabric
Step 3: Load data into a DataFrame with the schema
schema_df = spark.createDataFrame(data, schema=Test_schema_df)
Databricks

Fabric

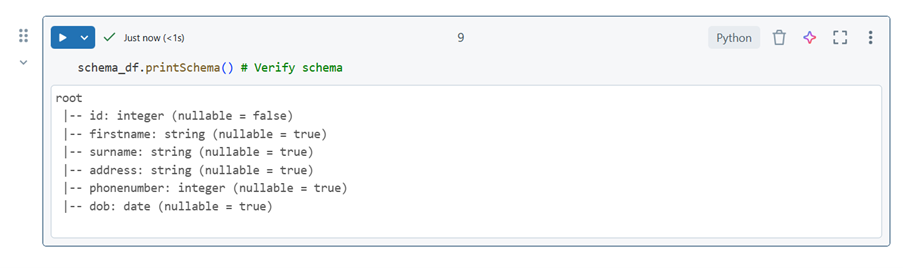
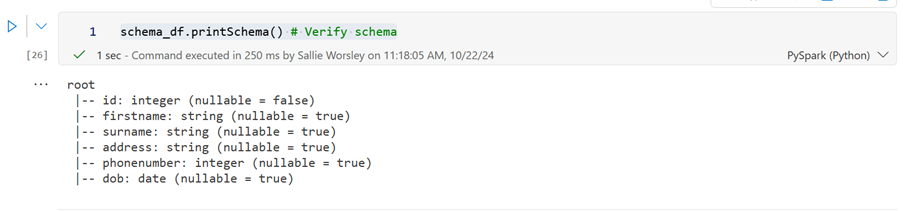
schema_df.printSchema() # Verify schema
Databricks
Fabric
Key Terms
- from datetime import datetime: This imports the datetime class from the datetime module, which is used to handle date and time data.
- data: The data that will be loaded as test data.
-
Alternative Method: You can also define the schema directly as a string and create the DataFrame.
Step 1: Define schema as a string
alternate_schema = “id INT, firstname STRING, surname STRING, address STRING, phonenumber INT, dob DATE”
Databricks

Fabric

Step 2: Create DataFrame with the alternative schema.
alternate_schema_df = spark.createDataFrame(data=data, schema=alternate_schema)
Databricks

Fabric

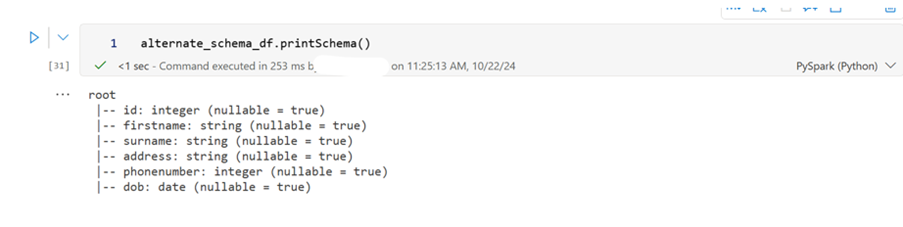
alternate_schema_df.printSchema()
Databricks
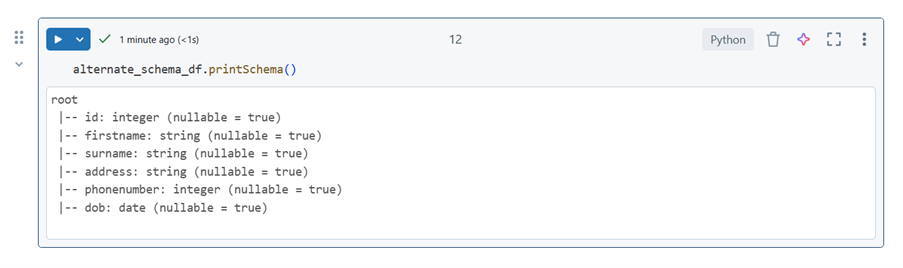
Fabric
Description of the different options outlined
- Using StructType and StructField: This method involves explicitly defining each field’s data type and nullability, providing clear and precise control over the schema.
- Defining Schema as a String: You can define the schema in a concise string format, which Spark will parse. This is simpler and quicker for straightforward schemas.
- Inferring Schema from Data: Spark can automatically infer the schema from the data itself, which is convenient for quick prototyping, but may not always get the data types exactly right.
-
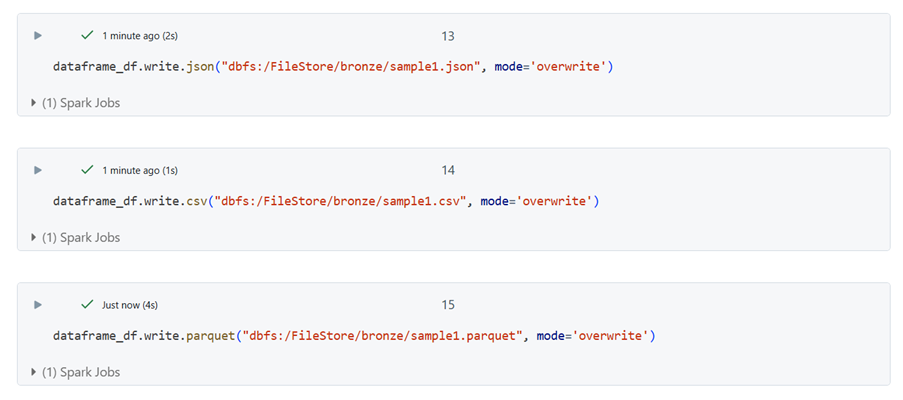
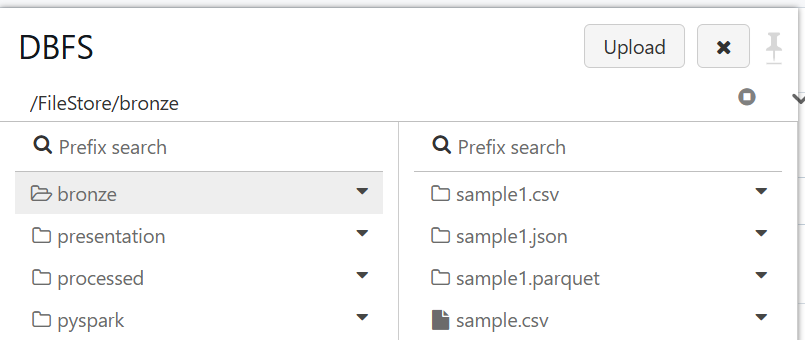
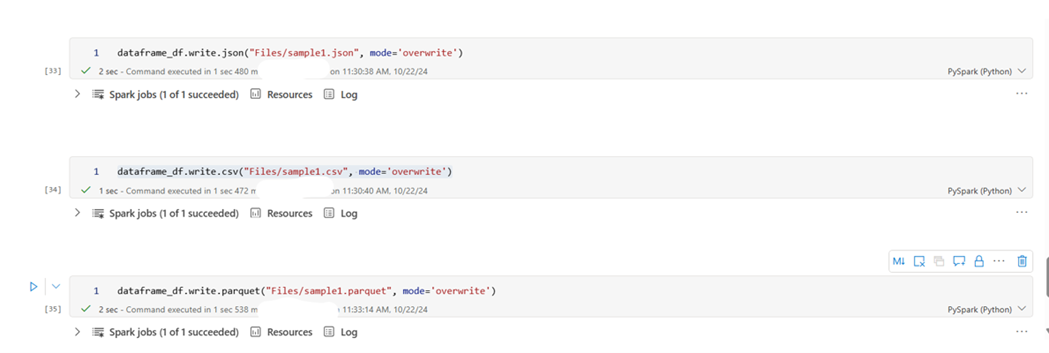
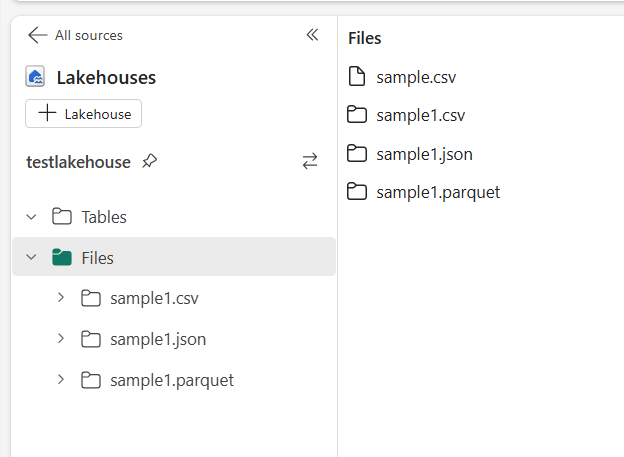
Writing to JSON, Parquet and CSV: You can save DataFrames in different formats:
Writing to JSON
dataframe_df.write.json(“filelocation”, mode=’overwrite’)
Writing to Parquet
dataframe_df.write.parquet(“filelocation”, mode=’overwrite’)
Writing to CSV
dataframe_df.write.csv(“filelocation”, mode=’overwrite’)
Databricks
Fabric
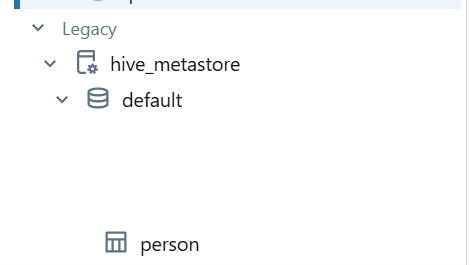
Save as a Delta table
dataframe_df.write.mode(“overwrite”).format(“delta”).saveAsTable(“Person”)
Databricks

Fabric

Modes:
- Overwrite: Replaces existing data at the specified location. Be cautious as this will delete any existing data.
- Append: Adds new data to the existing dataset.
- Ignore: Skips if data already exists
- Error (default): Throws an error if data already exists.
-
Common DataFrame Operations
-
Renaming Columns
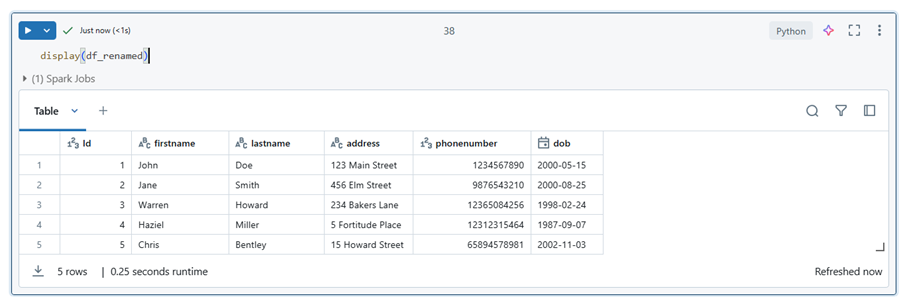
##Correct the spelling mistake and make names consistent.
df_renamed = dataframe_df.withColumnRenamed(“surname”, “lastname”) \
.withColumnRenamed(“firsname”, “firstname”)
Databricks

Fabric

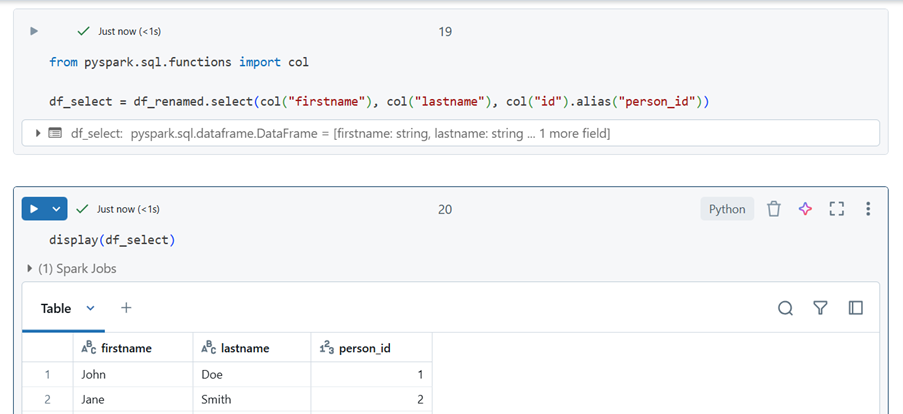
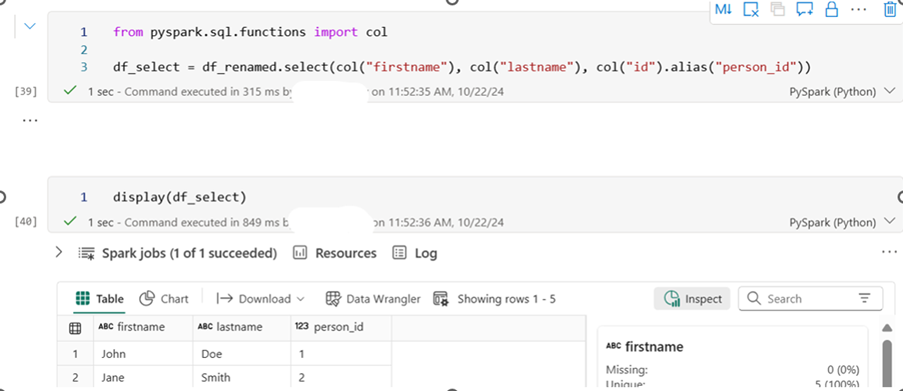
Selecting and Renaming Specific Columns
##import the module and select and column and re-name id to person_id
from pyspark.sql.functions import col
df_select = df_renamed.select(col(“firstname”), col(“lastname”), col(“id”).alias(“person_id”))
Databricks
Fabric
-
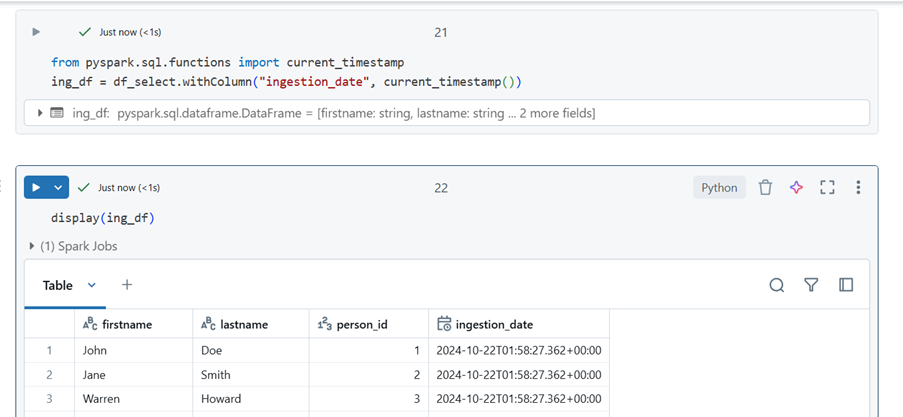
Adding Ingestion Date
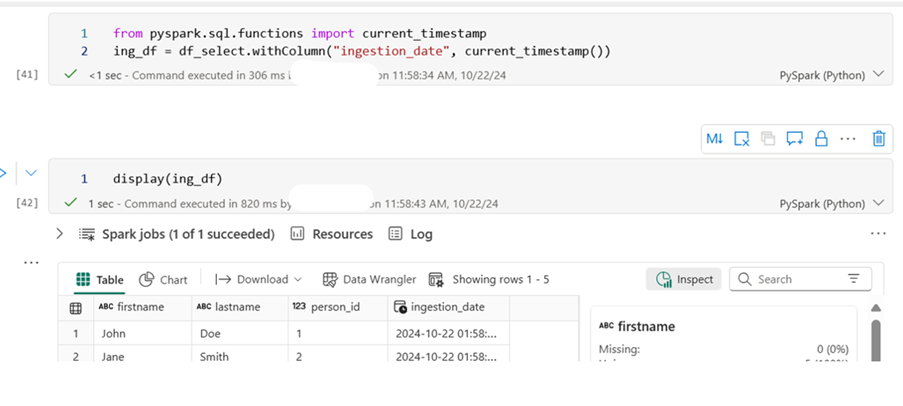
## Import current_timestamp and add Ingestion_date
from pyspark.sql.functions import current_timestamp
ing_df = df_select.withColumn(“ingestion_date”, current_timestamp())
Databricks
Fabric
-
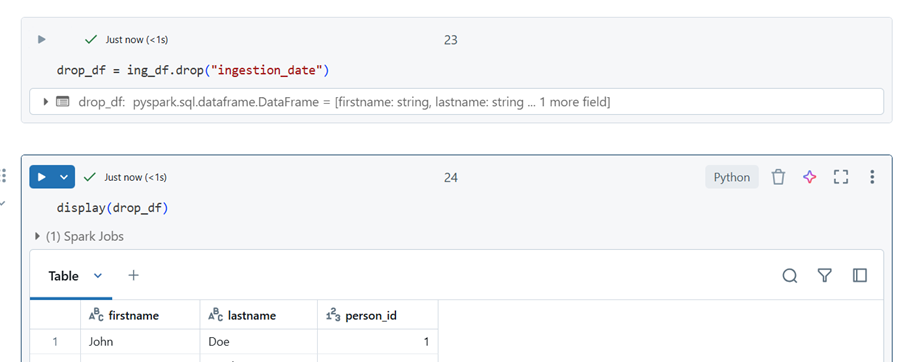
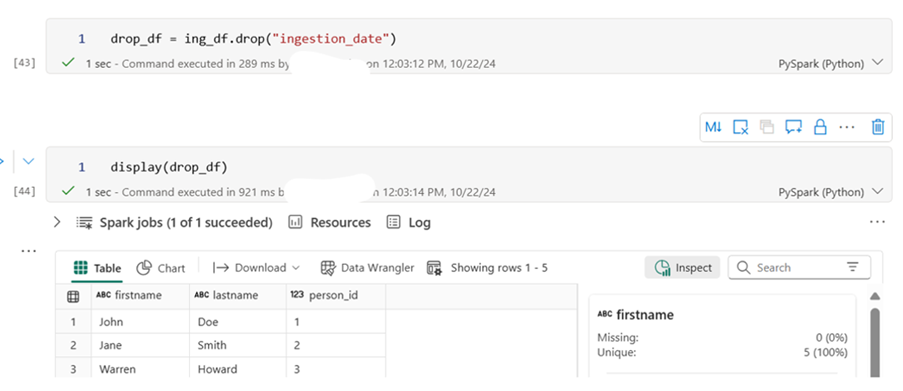
Dropping a Column
drop_df = ing_df.drop(“ingestion_date”)
Databricks
Fabric
-
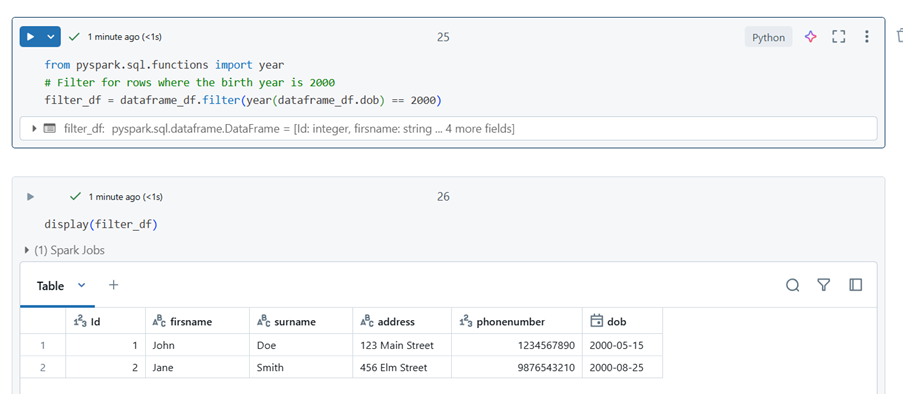
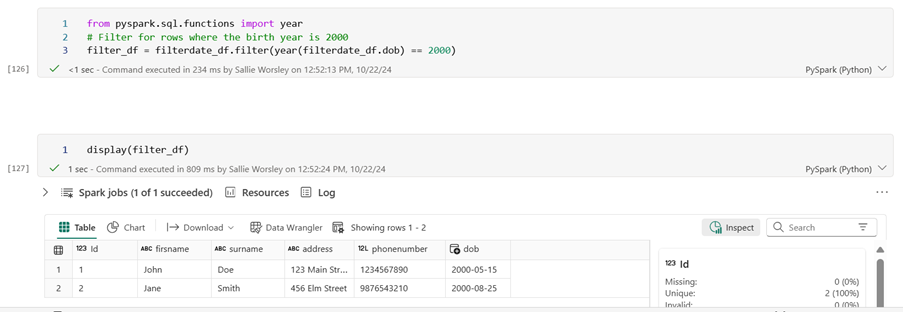
Filtering Data
from pyspark.sql.functions import year
#Filter for rows where the birth year is 2000
filter_df = dataframe_df.filter(year(dataframe_df.dob) == 2000)
Databricks
Fabric
When we initially imported the schema, Fabric did not correctly infer the date format.

The following alteration is required on the DataFrame:
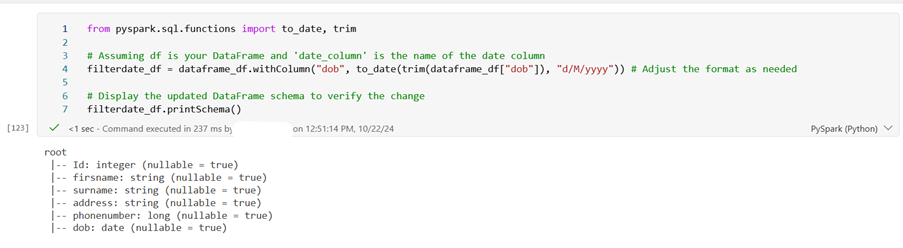
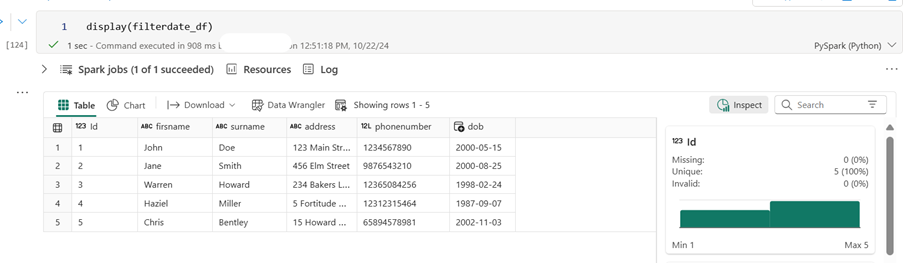
from pyspark.sql.functions import to_date, trim
filterdate_df = dataframe_df.withColumn(“dob”, to_date(trim(dataframe_df[“dob”]), “d/M/yyyy”)) # Adjust the format as needed
# Display the updated DataFrame schema to verify the change
filterdate_df.printSchema()
-
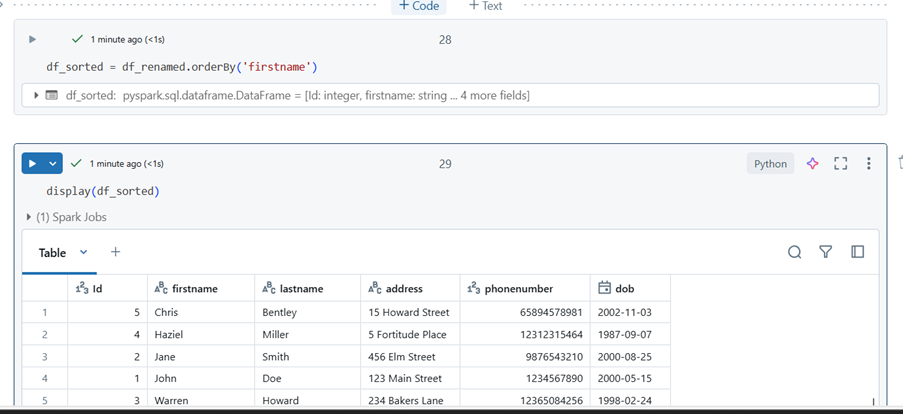
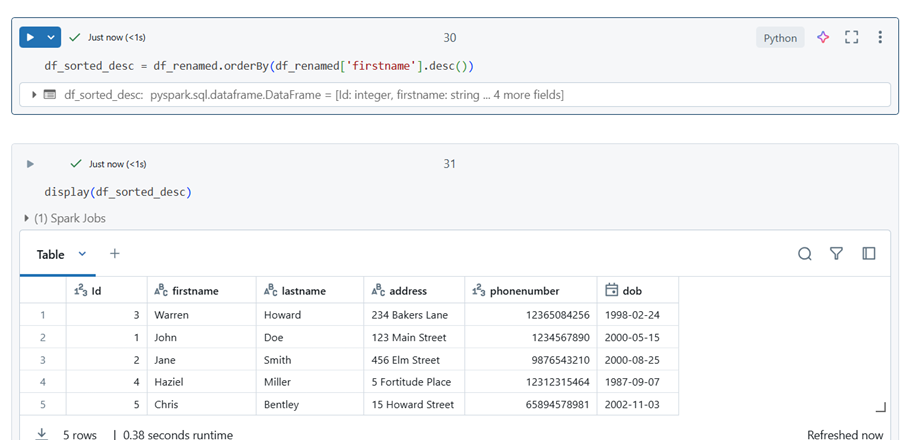
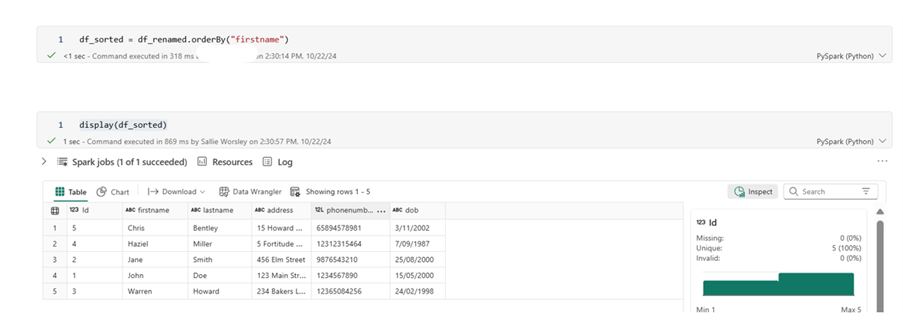
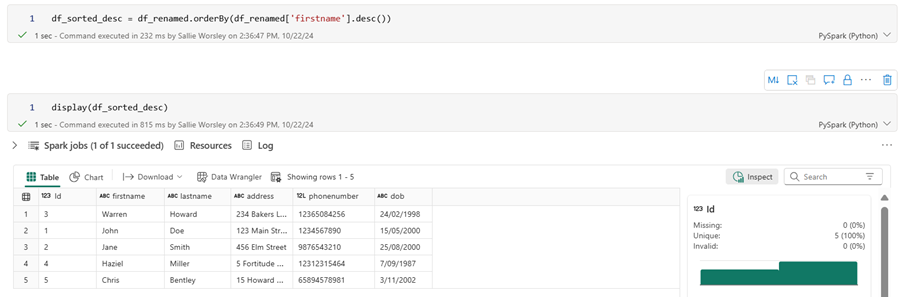
Sorting Data
df_sorted = df_renamed.orderBy(‘firstname’) ## sort ascending
df_sorted_desc = df_renamed.orderBy(df_renamed[‘firstname’].desc()) ## sort descending
Please note that the column must exist in the dataframe to be able to be sorted by.
Databricks
Ascending
Descending
Fabric
Ascending
Descending
-
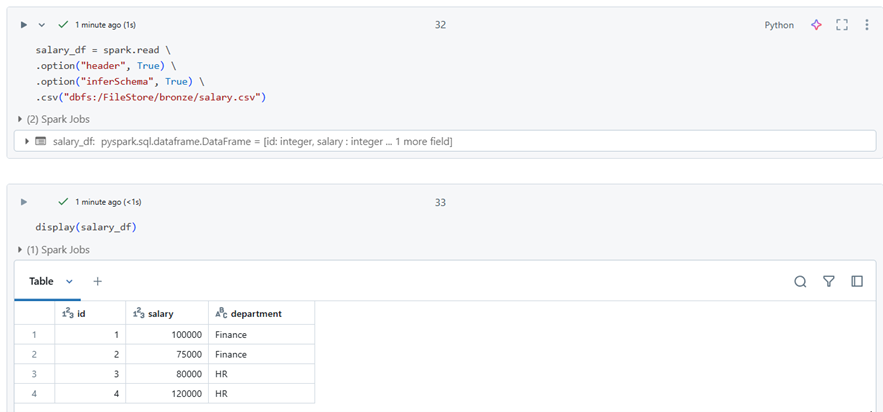
Aggregating Data
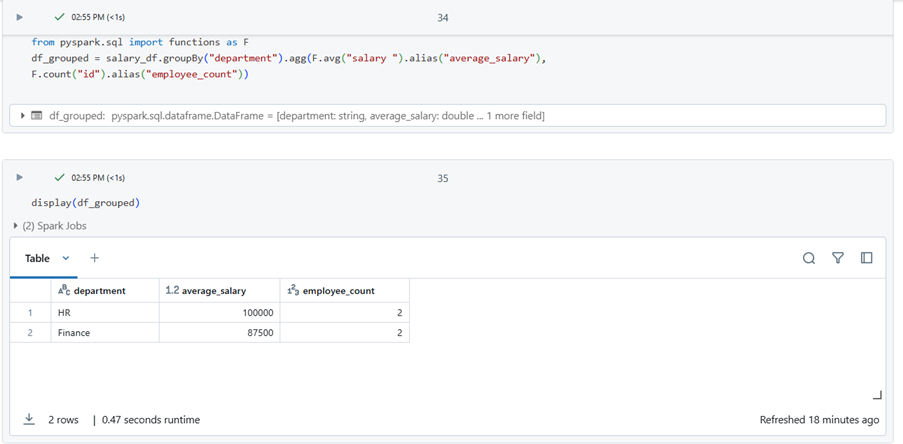
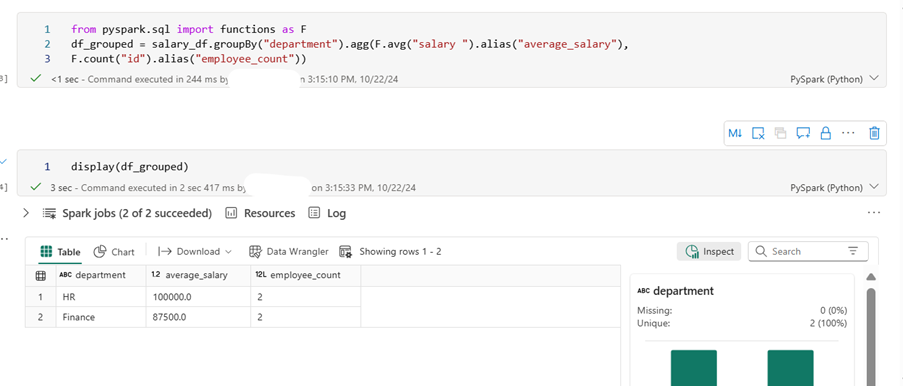
I have imported the following data to demonstrate data aggregation
Databricks
Fabric
from pyspark.sql import functions as F
df_grouped = salary_df.groupBy(“department”).agg(F.avg(“salary “).alias(“average_salary”),
F.count(“id”).alias(“employee_count”))
Databricks
Fabric
-
Joining DataFrames
-
Inner join
-
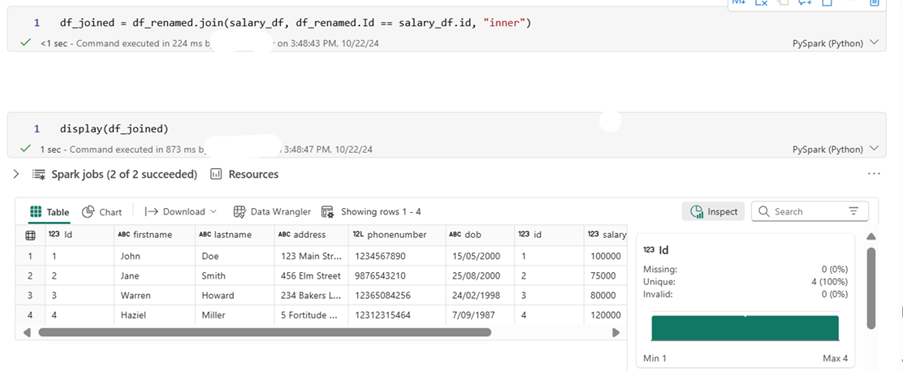
df_joined = df_renamed.join(salary_df, df_renamed.Id == salary_df.id, “inner”)
Databricks
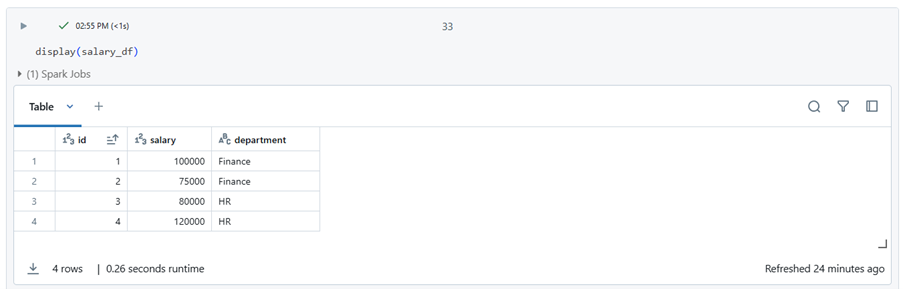
The inner join returns matching values from both DataFrames. We are using dataframe_df and salary_df, joining them on the id columns.
Databricks
Fabric
-
Left join
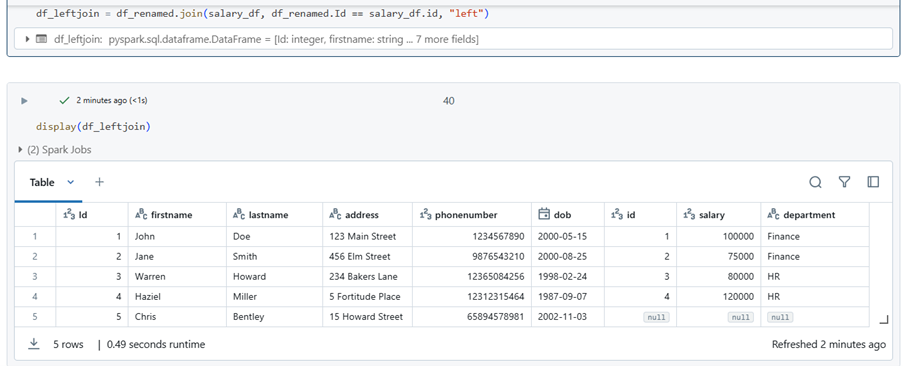
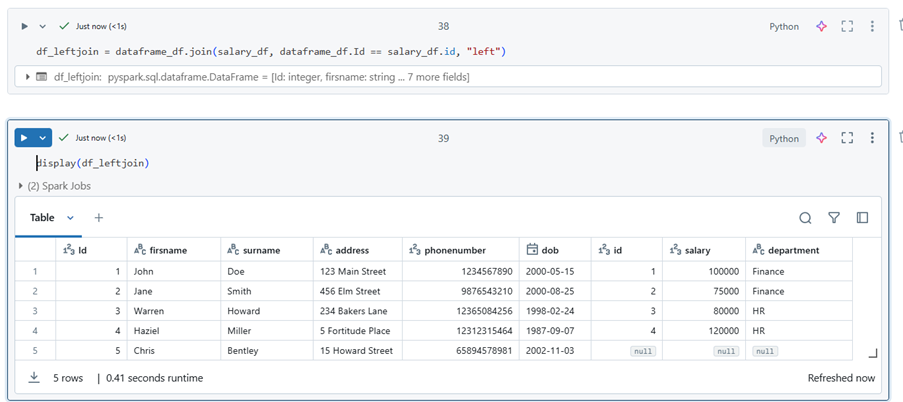
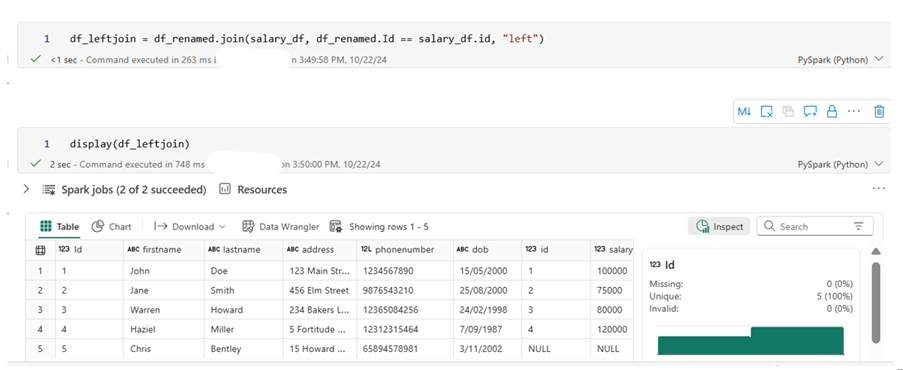
df_leftjoin = df_renamed.join(salary_df, df_renamed.Id == salary_df.id, “left”)
The left join is another common type of join. In this case, we have joined salary_df to dataframe_df, with dataframe_df as the left table. This join returns all rows from the left table and the matching values from the right table. If there are no matching values, the result will still include all rows from the left table, with nulls for the non-matching entries from the right table.
Databricks
Fabric
To learn more about how we can help you with your AI, contact our friendly team for a no-obligation discussion HERE