
Author: Etienne Oosthuysen
For those who have been involved in conventional Business Intelligence projects, you will be all too familiar with the likely contiguous chain of events and the likely outcome. It typically goes something like this: The idea is incubated by someone (very often this would be within ICT), a business case for a project is written, someone holding the purse strings approves it, suitable business and functional requirements are gathered-, written- and approved, the solution is architected and developed-, tested- and signed off, the solution is implemented, and voila, the business MIGHT use the solution.
These conventional solutions are problematic for a number of reasons:
Requirements are lukewarm at best – If the idea was not incubated by someone experiencing a real business pain point, or wanting to exploit a real opportunity, then the “requirements” gathered are always going to be skewed towards “what do you think you need” rather than “what do you know you need right now”.
Suboptimal outcome – Lukewarm requirements will lead to solutions that do not necessarily add value to the business as they are not based on real pain points or specific opportunities that need to be exploited. So when the formal SDLC process conclude the business may, in the spirit of trying to contribute to successful project outcomes, try to use the solution as is, or send it back for rework so that the solution at least satisfies some of their needs.
Low take-up rate – accepting a suboptimal solution so as to be a good team player, over time, usage will drop off as it’s not really serving a real need.
Costly rework and an expensive project – these issues means that the business often gets to see a final product late in the project lifecycle and often only then start thinking about what it could do for them if changes are applied to meet their real needs. The solution is sent back for changes, and that is very costly.
So what has changed?
Technology has finally caught up with what business users have been doing for a long time.
For many years, given the costly and problematic outcomes of conventional BI, users have often preferred access to the data they need, rather than fancy reports or analytics. They would simply download the data into Excel and create their own really useful BI (see related blog here https://exposedata.wordpress.com/2016/07/02/power-bi-and-microsoft-azure-whats-all-the-fuss-about/ ). This and the advent of a plethora of services in the form of Platform-, Infrastructure- and Software as a Service (PaaS, IaaS and SaaS), and more recently BI specific services such as Data Warehouse as a Service (DWaaS), are proving to be highly disruptive in the Analytics market, and true game changers.
How have this changed things?
In the end, the basic outcome is still the same. Getting data from some kind of source to the business in a format that they can consume by converting it to useful information.
But technology and clever architectures now allow for fast response to red-hot requirements. This is game-changing as solutions are now nimble and responsive and can, therefore, respond to requirements often discussed informally when pain points and/ or opportunities are highlighted in the course of the normal business day such as in meetings, over drinks with colleagues and at the “watercooler”. The trick is to recognize these “requirements” and to relate them back to the opportunities that the new world of data and analytics provide. If that can be done, then the solutions typically respond much better to these organic requirements vs. solutions that respond to requirements incubated and elicited in a much more formal way.
What are water cooler discussions?
I use this term to describe informal discussions around the organization about pain points or opportunities in the business. These pain points or opportunities represent organic requirements that should be responded to fast if they hold real value. This DOES NOT mean that formal requirements are no longer valid, not at all, but it means that we need to recognize that real requirements manifest itself in informal ways too. Here is an example of how a requirement can originate in a formal and in an informal way:
The problem
City planning realize that there are issues with parking availability as they receive 100s of calls each month from irate commuters stuck driving around looking for parking. It seems as if commuters are abandoning the city in favor of suburban shopping centers where ample parking is provided. This is not good for businesses in the city center, and not good for the city council.
Formal
The head of planning realizes that information (in the form of data) will be key to any of his decisions to deal with the problem, so requests reports on traffic volumes, finances and works management planning. It seems as if this data is not in the data warehouse, so a business analyst is employed to elicit the requirements around the reports required, and so the long and costly process starts.
Watercooler
The Head of Planning tells a colleague that he wishes he could expedite getting his hands on the information he needs but he has a limited budget so he cannot employ more resources to move his reports along quicker.
This is overheard by the Data Analytics consultant who realizes that in order to maximize supporting such an important decision, the Head of Planning will have to look at the issue from multiple angles which will likely not be provided by such formal reports. The data he needs, I.e. traffic volumes, finances and works management planning must be blended with other contextual data such as weather, events, date and time of day.
The consultant knows that:
- The city already holds traffic volumes, finance date and works management planning across fragmented source systems.
- The city already collects millions of sensor data per day – parking, traffic flow, commuter flow.
- There are heaps of contextual data out there which is easy to access – weather, events, city businesses financial results, employment figures, etc.
- The city already has a cloud subscription where services such as IaaS, but especially PaaS and SaaS and DWaaS can quickly be added and configured so as to allow for the collection, blending, storage, processing of data at a fraction of the cost of achieving the same on-premise.
- That the cloud subscription allows for data science and predictive analytical activities to complement the collection, blending, storage, processing of data.
He calls a meeting with the Head of Planning who is intrigued with the idea and the quick return on investment (ROI) at a fraction of the cost, and commissions the consultant to provide a proof of concept (POC) on the matter.
From water cooler discussion to the solution in record time
In my example (which is based one of our real-world examples using Microsoft Azure) the city has an existing investment in a cloud service. Also, note that I provide a high-level resource mapping of the POC and solution at the end of this blog for both Amazon Web Services (AWS)® and Microsoft Azure®.
- The process starts with a POC. Either in a free trial subscription or in the customer’s existing cloud provider such as AWS or Azure.
- The preference is to keep the solution server-less and only opt for IaaS where resources cannot be provided as PaaS or SaaS.
- IoT parking data form the basis of the solution and both real-time flows plus history is required.
- Weather data, traffic flows into and around the city, events, and time of day will help add important context when predicting times of parking through peaks and troughs.
- Organisational works management planning data will further enhance better parking planning.
- Whilst business financial results show the impact, and more importantly lost opportunity cost on businesses if people abandoned the city in favor of suburban shopping centers.
- The processing and storage of the sheer volume of data are achieved at a fraction of the cost than previously envisaged by the business.
- The resulting solution is not a replacement for any corporate data warehouse, but complementary to it. Any existing data repository can be viewed as additional and useful contextual data in this new data analytics landscape.
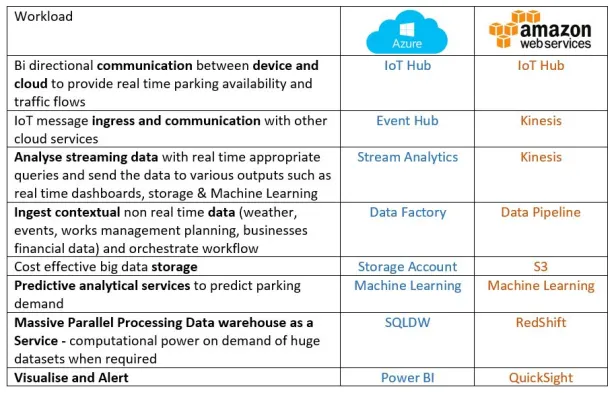
The POC architecture involves the following resources (both Azure and AWS are shown):
Please note that the diagram below by no means implies a detailed design, but is a true representation of the high-level architecture we used to achieve the specific solution.
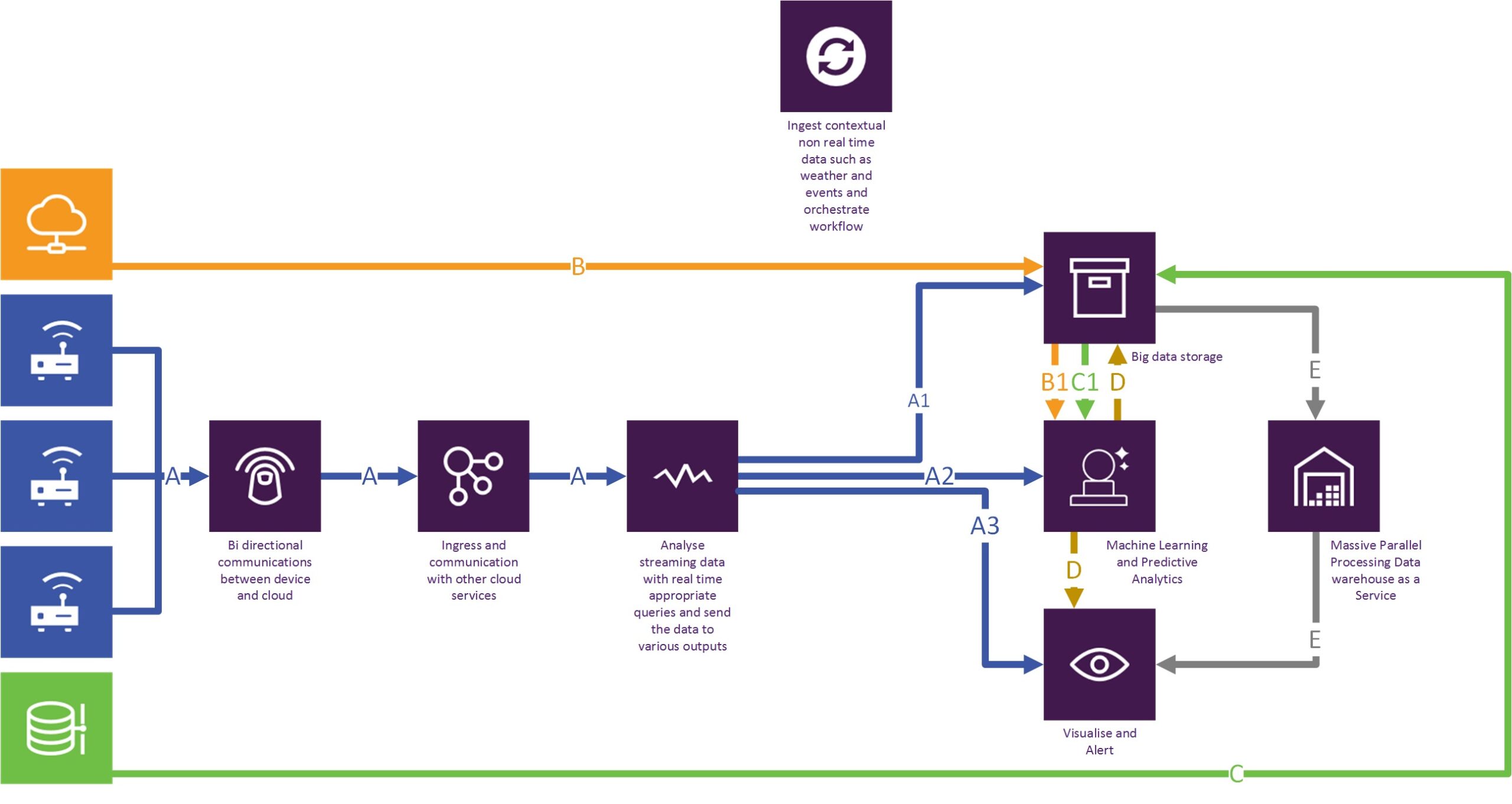
Data flow patterns
- A: IOT – Sensor originated real-time data;
o A1: Into storage;
o A2: Into predictive analytics where it is blended with B and C;
o A3: Directly into real-time visualizations;
- B: Additional contextual data from publicly available sources such as weather, events, business financial performance, into storage;
o B1: Into predictive analytics where it is blended with A and C;
- C: On-premise data such as works management, into storage;
o C1: Into predictive analytics where it is blended with A and B;
- D: Predictive analytical results into real-time visualizations, and also to storage for historical reporting;
- E: Massive parallel processing, scalability and on-demand compute where and when required and supporting visual reporting;
Outcome
The result of such a real-world example POC was the realization by the business that very deep insights can be achieved by leveraging the appropriate data wherever it exists and by cleverly architecting solutions with components and services within easy reach, superior outcomes can be achieved fast.
The building blocks created in the POC was adopted and extended into a full production solution and it set the direction for future data analytical workloads.