
The Power BI and Fabric Summit 2024 united an exceptional community of data enthusiasts, and our Purple Peeps thoroughly enjoyed diving into the latest trends and innovations. Here are our top session picks and insights, from Juan, Sallie, Teresa, and Heidi.
Juan’s Insights
Data Management Gets a Power-Up With Fabric Onelake
Microsoft’s demos showcasing the capabilities of Fabric OneLake at the PBI & Fabric Summit 2024 grabbed my attention. It’s clear they’re reshaping how we approach data management, making it more intuitive and interconnected than ever before.
- Why It Stands Out: OneLake’s introduction is like finding a new, streamlined path in the often complex journey of data integration. It breaks down barriers, offering a unified view of data across an organisation through its unified virtual storage solution. It’s like having all your data, regardless of its source, accessible in one coherent, virtual space. That’s the simplicity and efficiency OneLake promises.
- Core Features: The platform shines with features aimed at enhancing data fluidity and governance. Virtual storage, unified governance with holistic data lineage visibility, the ability to host multiple lakehouses within a single ecosystem, and its foundation in the open-source Delta Lake format, underscore OneLake’s commitment to flexibility and seamless data integration.
- Enhancing Accessibility: OneLake simplifies the data landscape with functionalities like Shortcuts for lakehouses, Mirroring for data warehouses, Direct Lake for Power BI, and Storage Explorer for a file-system-like experience for all your data. These tools are designed not just for ease of use but to foster an environment where data is more accessible and near real-time, all while avoiding unnecessary data duplication. They empower users to navigate and utilise data with unprecedented efficiency, promoting a collaborative and agile workflow.
- Limitations: Despite the innovative approach, it’s not a one-size-fits-all solution. Primarily designed for analytical workloads, it might not suit operational applications due to its read-optimized storage framework. Additionally, its Shortcut and Mirroring features are currently limited to certain storage locations and databases, excluding platforms like AWS Redshift and GCP BigQuery. Also, while OneLake Explorer aims to simplify data navigation, the predominance of delta and parquet files can make direct data interpretation challenging for users, potentially limiting its immediate usefulness without further enhancements.
The key takeaway here is that Microsoft Fabric OneLake redefines the concept of a central data repository, and at the summit, it felt like a pivotal turning point in data management strategy. Its blend of innovation and practicality makes it a compelling choice for businesses looking to streamline their data processes. With OneLake, Microsoft is not just offering a product but a new way of thinking about and interacting with data, promising to drive efficiency and insight across organisations. So, if you want to drive this wave and maximise the value of your data assets, incorporating OneLake into your roadmap is definitely worth considering.
Domains: A Microsoft Fabric Approach to Decentralised Data Ownership
Say goodbye to data silos! Fabric Domains is here to revolutionise how you organise and manage your data. Imagine them as dedicated compartments where different teams in your business (like Finance, Sales, and Marketing) can curate their own data as products. It’s like having multiple, neatly organised libraries instead of one massive, jumbled bookshelf. Here’s how Domains makes your life easier:
- Easy Data Discovery: Navigate through your data effortlessly. Fabric Domains organises data artifacts into logical groups, transforming the chaos of data lakes and pipelines into a streamlined, searchable repository.
- Team Data Ownership: Teams responsible for a specific business area directly control the data and all related artifacts within their domain. This ensures that it reflects their unique expertise and drives more meaningful insights.
- Seamless Collaboration: Need data from another team? No problem! Domains promote secure data sharing while respecting ownership and governance controls.
Notably, Microsoft Fabric Domains embraces the data mesh philosophy, where data is treated as a valuable product. Picture a world where every business unit controls and curates its data journey, leading to improved quality, deeper insights, and accelerated innovation.
Additionally, Workspaces offer fine-grained control over how data is managed and shared. Demonstrations from Microsoft MVPs have illustrated how Workspaces function as ‘project compartments’ where different teams can work on their data-driven ideas without disrupting each other. Teams can design and refine their data models and reports within their designated Workspace, ensuring that once a data product is fully developed and tested, it can be confidently rolled out for broader organisational adoption in a “Production Workspace”.
In sum, Fabric Domains is not just a new tool in your data management toolkit; they represent a paradigm shift towards a more organised, autonomous, and collaborative approach to data management. By bridging the gaps between teams, streamlining data discovery, and ensuring data ownership, Fabric Domains paves the way for a future where data silos are a thing of the past.
Sallie’s Insights
In the rapidly evolving realm of data management, Microsoft has introduced Microsoft Fabric, a Software as a Service (SaaS) tool aimed at simplifying the extraction of valuable insights from data. This unified platform is crafted to free data professionals and citizen developers from the complexities of configuring disparate services and connections, placing a renewed emphasis on maximising the value derived from data.
OneLake: Where Collaboration Meets Simplicity
Introducing OneLake, Microsoft Fabric’s addition to the data management toolkit. Picture it as the OneDrive for data, streamlining the sharing, composition, and linking of data across Azure and other clouds. Positioned as a single, unified, logical data lake for entire organisations, OneLake eliminates the need for juggling multiple lakes. Governed by default and boasting distributed ownership, OneLake ensures that every Fabric tenant has precisely one, trimming unnecessary setup overhead.
Copilot for Data Engineers: Your Data Wingman
 Enter Copilot for Data Engineers, changing the data game by translating detailed human language instructions into PySpark code. Empowering a broader range of professionals, Copilot makes the power of data accessible without the need for extensive coding knowledge.
Enter Copilot for Data Engineers, changing the data game by translating detailed human language instructions into PySpark code. Empowering a broader range of professionals, Copilot makes the power of data accessible without the need for extensive coding knowledge.
Data Engineering Simplified: It’s the Little Things
In the realm of data engineering, Microsoft Fabric’s Data Factory combines the strengths of Azure Data Factory and Power Query Dataflows. Small yet impactful features, like the Outlook activity in the Data Factory Pipeline, simplify email alert configurations, enhancing the user-friendly approach and overall data engineering experience.
SQL Analytics Endpoint: The Data Maestro
Microsoft Fabric’s Data Engineering introduces the SQL analytics endpoint, a powerful tool for Lakehouse delta tables. This SQL-based experience lets users analyse data, utilise T-SQL language, create views, and implement SQL security measures. Accessing the SQL analytics endpoint is a breeze. Just select the corresponding item in the workspace view or switch to the dedicated SQL analytics endpoint mode in Lakehouse Explorer. Alternatively, you can copy the SQL connection string and use familiar tools such as SSMS leveraging Microsoft Entra’s account management. Operating exclusively in read-only mode over lakehouse delta tables, the SQL analytics endpoint becomes the go-to for data retrieval.
Microsoft Fabric stands as a solution that simplifies complex processes in data management. Through seamless integration, user-friendly interfaces, and innovative features like Copilot, Fabric empowers data professionals and citizen developers to unlock the true potential of data without being bogged down by intricate configurations, in this data-driven era.
Teresa’s Insights
The 2024 Fabric and Power BI Summit brought forth several noteworthy updates, providing users with valuable tools to streamline their work in Power BI.
A focus in my daily work is to create reports that provide consumers with a seamless experience that is intuitive to use and provides the information they need, so to this, I was particularly interested in sessions that focussed on achieving this goal through better modelling and techniques for better storytelling.
Getting Started with Calculation Groups in Power BI Desktop – by Bernat Agullo
One significant improvement is the integration of Model Explorer and Calculation Groups directly into Power BI Desktop. Unlike before, where installing the external tool Tabular Editor was necessary, a new preview feature now allows us to perform these tasks within the Power BI interface. Activating the preview feature enables a new section called Model in the model view, where users can create calculation groups without navigating away from the Desktop.
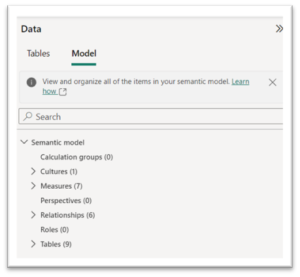
I have worked with calculation groups at a basic level before, so this session was particularly useful for me as a reminder of how calculation groups can be utilised.
Calculation groups prove to be a practical solution for applying a single calculation across multiple measures. In the absence of calculation groups, we would need to create separate measures for variations like Budget, Actual, and Variance. For instance, crafting measures for the Previous Year required creating an additional measure for each base measure (i.e. Budget Previous Year, Actual Previous Year, and Variance Previous Year). The DAX for Budget Previous Year might look like this:
![]()
Calculation groups simplify this process by creating a virtual table with a column named Previous Year, which is built using the DAX above, but substituting the [Budget] with SELECTEDMEASURE(). This column can then be utilised as a header or a filter in visuals or other DAX formulas.
Some other common use cases for calculation groups include:
- Extending the above example to include other time intelligence functions like month-to-date, quarter-to-date, etc.
- when report consumers may want to change formatting within a report, i.e. dynamically switch between raw, thousands and millions
- currency conversions: be able to switch between different currencies without creating a measure for each one
- different forecasting scenarios such as expected, better than expected, worse than expected
- and the list goes on!
On a side note, it’s worth knowing that once you have a calculation group in your model, you can no longer use implicit measures – which is not a bad thing. If you have existing reports with visuals that use implicit measures, these will still work, but new ones cannot be added.
Leveraging DAX for Advanced Data Storytelling in Power BI – Benjamin Ejzenberg:
Benjamin shared insights on using DAX for advanced storytelling. This was a great session for those of us who want to use DAX with conditional formatting for a dynamic end-user experience. Ben had ten different examples of how to apply DAX in this way; these were my favourites.
One approach highlighted was using a measure to emphasise the minimum and maximum columns on a chart. The measure identifies the max and min values, which are then used to assign colours to the columns. So simple, but one I often forget is possible.
Another technique involved implementing dynamic reference lines using a numeric parameter. With this one, the user uses a slider to choose a target value (this could be used for a what-if type analysis, too), and the column colours change according to the selected value – showing green for records above the selected target and leaving the rest a base colour.
Modern Power Query User Interface in Power BI Desktop – Miguel Escobar
Power Query in Power BI Desktop is set for a visual makeover and will be launched into preview soon! The new UI, based on the Power Query online user interface, will be the foundation for future development.
The things I like about the new interface include the diagram view, which illustrates the query steps and provides tooltips for detailed step information.
The schema view, which reveals field names and data types, allows us to make changes without processing all data rows and is particularly useful for large datasets. Notably, the new power query interface means we can now add a Rank column, which is currently exclusive to the online version.
The enhanced interface also consolidates query steps, data, and script (advanced view) on a single screen, which is very useful, especially when you just want to jump in and edit the M code directly but not have to navigate back and forth to see if it has worked. – very excited for this one!
There is so much more I could have written about, and as usual, I leave these summits inspired by and grateful for the knowledge so willingly shared by the Power BI (and now Fabric) community!
Heidi’s Insights
The Power BI and Fabric Summit is the premier virtual event of the year, and this one was no exception. With last year’s announcement of Microsoft Fabric, there were a number of sessions focused on that while still having in-depth sessions around Power BI performance tuning and report design.
There were a few key themes that stuck out for me.
- Microsoft Fabric is an enabler for fusion teams to all work in the same platform, with One Lake providing that single place for all personas to interface with data. No longer needing conversations around copy data so another team member can work with it.
- It’s no longer an argument of picking a platform based on team skills in data engineering, as both Python and T-SQL developers can work with their preferred tools against the same data side by side. Python developers can use notebooks, while T-SQL developers can use stored procedures.
- Power BI is here to stay: While Power BI has become an experience within Fabric, it doesn’t replace Power BI and/or approaches to data problems. It enables more options and capabilities that have a seamless integration with Power BI. An example of this is before, there were two modes: import or direct query. With Fabric, we now also have Direct Lake mode, a seamlessly refreshless approach with anticipated better-than-import performance.
- Real-time analytics: A lot of the time, the focus for real-time analytics is from a reporting perspective, the need/want to have data visualised in real-time however, with Microsoft’s KQL database, this changes the conversation on real-time to real-time ingestion and then optional real-time analytics